Sandboxing Kubernetes workloads with gVisor and Falco

Most of what will be discussed during this post, can be found in more details on gVisor's website, I'll merely be trying to sum some of it up and vulgarize some concepts but I highly recommend you to go read it, it's amazingly made for a documentation.

All of the files used in this post are available on my github.
 NoOverflow
NoOverflowWhy do we need to sandbox containers ?
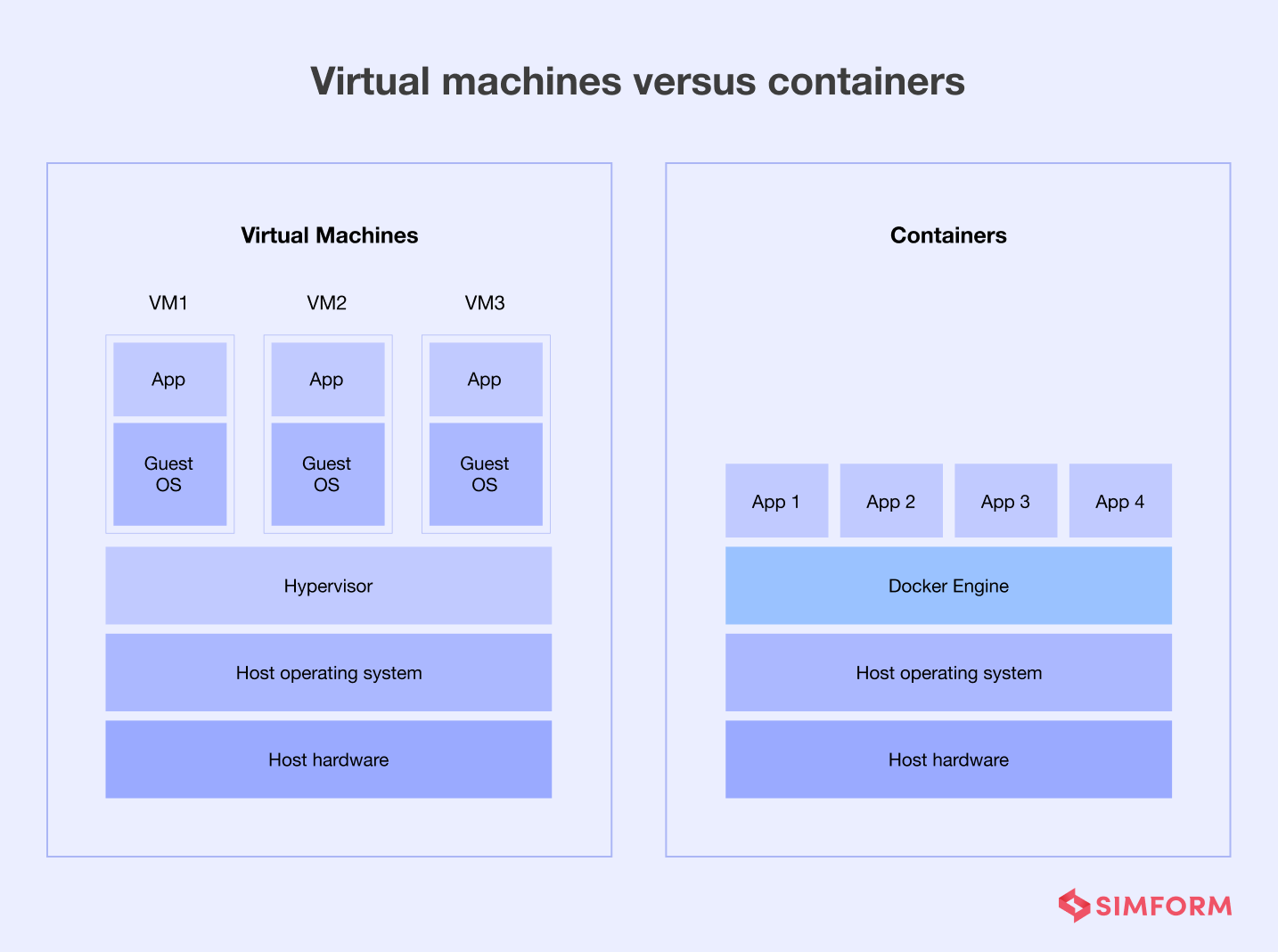
If you're just starting your journey with containers, or if you've only just heard of them, you might think that containers are akin to virtual machines in that they allow to completely isolate workloads running inside them from the host, and from other containers. Unfortunately, the line is way more blurry than that.
Then what are containers ?
This honestly could be the subject of a whole other post, and might be one day, but we'll keep it simple for today.
A container is, if we reduce it to the minimum, nothing more than a Linux process isolated in some ways using the wonderful namespacing features provided by the Linux kernel (cgroups, net_namespace ...) (we'll skip the overlay-ing parts for today).
While this reduces the crossover surface between multiple workloads, this does not provide complete isolation from the host, and exploits can result in code being run on the host (container breakouts). These exploits are in-part due to the fact that all containers share the same instance of the Linux kernel, which is not the case for virtual machines.
So why do we use them and not run VMs for everything ?
There are plenty of reasons why the industry standard is moving from VMs to containers. Sure, containers on the same host share the same kernel and that can be an issue, but this also means you don't have to run N instances of the same kernel if you're hosting multiple virtual machines. This greatly reduces the resource impact, allowing more processing power to be used for actual workloads.
This also means that the startup time of a container is negligible compared to a VM as the latter has to perform BIOS/UEFI initialization, boot load etc.; while the new container can just piggyback on the already running kernel and start directly.
Containers also allow sharing workloads in a self-contained way, combined with the reduced startup time, this allows orchestrators like Kubernetes to run thousands of these at once, all while moving them on different nodes if needed.
I could go on with the advantages of containers over traditional VMs, but it's not the subject of this post...
How can we reduce the security impact containers inherently come with ?
Finally, after all this yapping, we come to the interesting part of the post. What are the ways currently to protect leaks between containers and their host ? There are a few solutions, at runtime level, that come to mind:
- Kernel security modules, such as AppArmor or SELinux : These are kernel modules that filter the capabilities of processes, such as restricting access to certain files, preventing the use of a list of syscalls... They can be (very) roughly compared to firewalls.
Coming up with sensible restriction profiles for each of your container images can be quite time-consuming as, even a single file or syscall missing will result in your workload crashing. - Security-oriented container runtimes: these are specific runtime implementing the OCI standard focused on increased workload isolation. And today we're trying one of them, gVisor's runsc.
What is gVisor ?
gVisor is a container security platform, its main "component" is runsc, an OCI-compliant container runtime that will act as a sandbox, isolating your containers from the host using an intermediate layer (we'll see what this layer is later). It also provides ways to monitor what's going on in that sandbox through syscall tracing, and lots of other goodies we'll check out right now.
How does it work ?
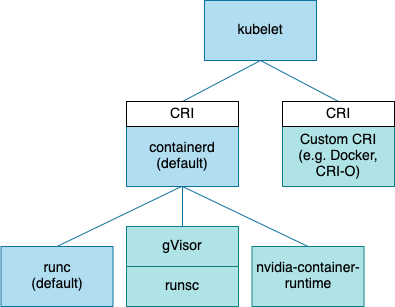
Let's begin by talking about how runsc doesn't work, or rather, what it isn't:
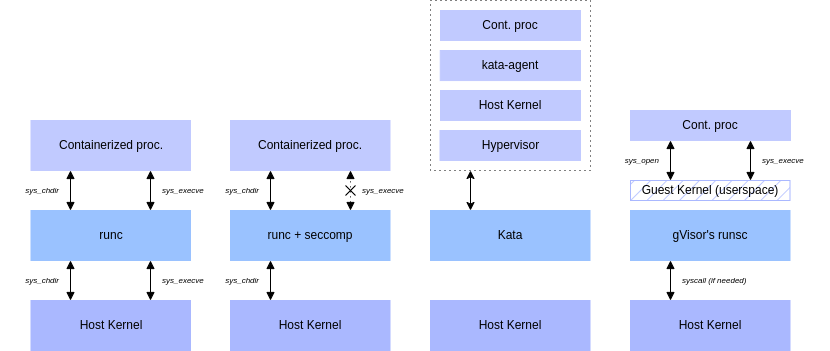
runscis not a syscall filter, it doesn't have a list of seemingly innocent calls that it would allow, or not, and is not just passing them through.runscdoes not use lightweight virtualization to provide isolation like some other runtime do, such as Kata.
Instead, runsc provides something that could be compared to a "guest" kernel (similar to User Mode Linux), this guest kernel has the job of handling the system calls of the container instead of just forwarding them to the host.
Obviously, since containers must still be able to mount files or perform specific actions, runsc has to make system calls to the host in order to perform these actions, but these are kept to a minimum and only if allowed.
A good analogy of runsc I thought of recently would be the movie "The Truman's show", while seemingly a weird one, the container is stuck in a sandbox, thinking it's in a real system and only given what is needed to survive (syscalls, files, network...) by an exterior power (the guest kernel).
Testing gVisor
Deploying it on Kubernetes
For testing purposes, I pieced together a quick privileged DaemonSet that downloads and installs the runsc runtime. You will probably have to modify it slightly, especially the "config.toml" part.
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app.kubernetes.io/component: configurator
app.kubernetes.io/name: runsc-configure-node
name: runsc-configure-node
namespace: kube-system
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/component: configurator
app.kubernetes.io/name: runsc-configure-node
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/component: configurator
app.kubernetes.io/name: runsc-configure-node
name: runsc-configure-node
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: k8s.nefast.me/runsc-configured
operator: DoesNotExist
containers:
- command:
- bash
- -c
- |
set -xe
chroot /host /bin/bash <<"EOT"
setup_runsc() {
ARCH=$(uname -m)
URL=https://storage.googleapis.com/gvisor/releases/release/latest/${ARCH}
wget ${URL}/runsc ${URL}/runsc.sha512 \
${URL}/containerd-shim-runsc-v1 ${URL}/containerd-shim-runsc-v1.sha512
sha512sum -c runsc.sha512 \
-c containerd-shim-runsc-v1.sha512
rm -f *.sha512
chmod a+rx runsc containerd-shim-runsc-v1
mv runsc containerd-shim-runsc-v1 /usr/local/bin
# That's a super bad way to do it, but I cba to parse the TOML and merge it properly
sed -i '/\[plugins\."io\.containerd\.grpc\.v1\.cri"\]/a\ default_runtime_name = "runc"' /etc/containerd/config.toml
cat <<EOF | sudo tee -a /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runsc]
runtime_type = "io.containerd.runsc.v1"
EOF
}
set -xe
setup_runsc
systemctl restart containerd
EOT
kubectl label node "$NODE_NAME" k8s.nefast.me/runsc-configured=$(date +%s)
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: alpine/k8s:1.25.3
name: runsc-install
securityContext:
privileged: true
runAsUser: 0
volumeMounts:
- mountPath: /host
name: host
dnsPolicy: ClusterFirst
hostNetwork: true
hostPID: true
restartPolicy: Always
volumes:
- hostPath:
path: /
type: Directory
name: host
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdatehttps://github.com/NoOverflow/gvisor-falco-blog-post/blob/master/runsc-daemonset.yaml
Once that runtime is installed, let Kubernetes know about it so it can use it.
apiVersion: node.k8s.io/v1
handler: runsc
kind: RuntimeClass
metadata:
name: gvisorhttps://github.com/NoOverflow/gvisor-falco-blog-post/blob/master/gvisor-runtimeclass.yaml
Let's start a pod and confirm that everything work as intended:
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: default
spec:
containers:
- image: nginx:latest
imagePullPolicy: Always
name: sandboxed-container
resources:
requests:
cpu: 100m
dnsPolicy: ClusterFirst
restartPolicy: Always
runtimeClassName: gvisorhttps://github.com/NoOverflow/gvisor-falco-blog-post/blob/master/demo-pod.yaml
Once that pod starts, you can confirm that you're indeed running in a sandbox by reading the kernel logs in the pod.
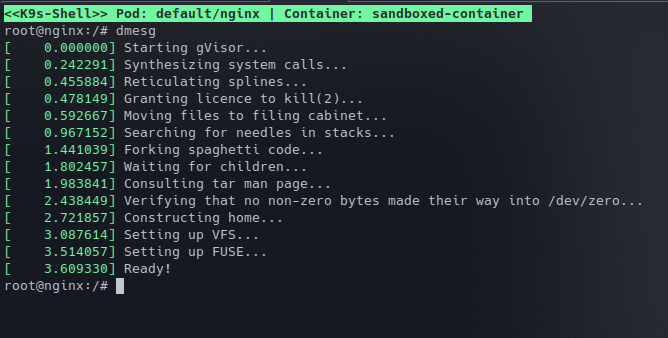
Congratulations, you just ran your first sandboxed container, now how do we look inside, from outside ?
Monitoring gVisor
Now, how do we know what our processes are doing in their own little sandboxes, since traditional supervision tools cannot "see" what's going on in them ? gVisor exposes these traces but we'll have to exploit them using another tool called Falco (+FalcoSideKick).
Falco "is a cloud native security tool that provides runtime security across hosts, containers, Kubernetes, and cloud environments. It leverages custom rules on Linux kernel events and other data sources through plugins, enriching event data with contextual metadata to deliver real-time alerts."
Basically, it takes a lot of raw data (in our case, traces) and extracts intelligence from it.
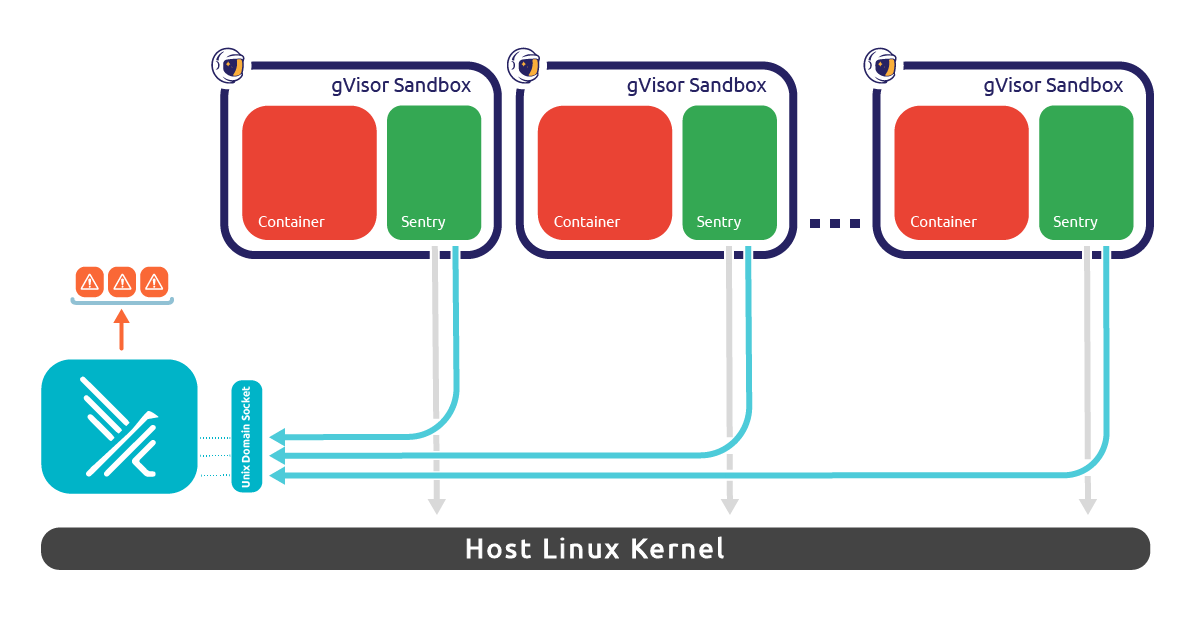
To install Falco, we'll use the Helm chart, modifying it to enable the gVisor driver (Falco supports other runtimes, but we're only interested in gVisor for now). Here are the values I've used with a quick description of what they do:
# This is a pod that expose a web interface for falco
falcosidekick:
enabled: true
webui:
enabled: true
ingress:
enabled: true
hosts:
- host: falco.MY_HOST_CHANGE_ME
paths:
- path: /
# These will be used to gather detection statistics in Prometheus...
serviceMonitor:
create: true
# ...and create the corresponding dashboards.
grafana:
dashboards:
enabled: true
driver:
enabled: true
kind: gvisor
gvisor:
enabled: true
runsc:
# The path that contains the runsc binary on your nodes
path: /usr/local/bin
# The root folder of container states (*.state files)
# the falco helm chart automatically appends /k8s.io to it
root: /run/containerd/runsc
# The falco init container will append a configuration line for runsc in it, so make sure it exists, also make sure it contains a [runsc_config] block
config: /run/containerd/runsc/config.tomlhttps://github.com/NoOverflow/gvisor-falco-blog-post/blob/master/falco-values.yaml
With that deployed, we can access the Falco SideKick UI (make sure you did change the host url in the values file 😉):
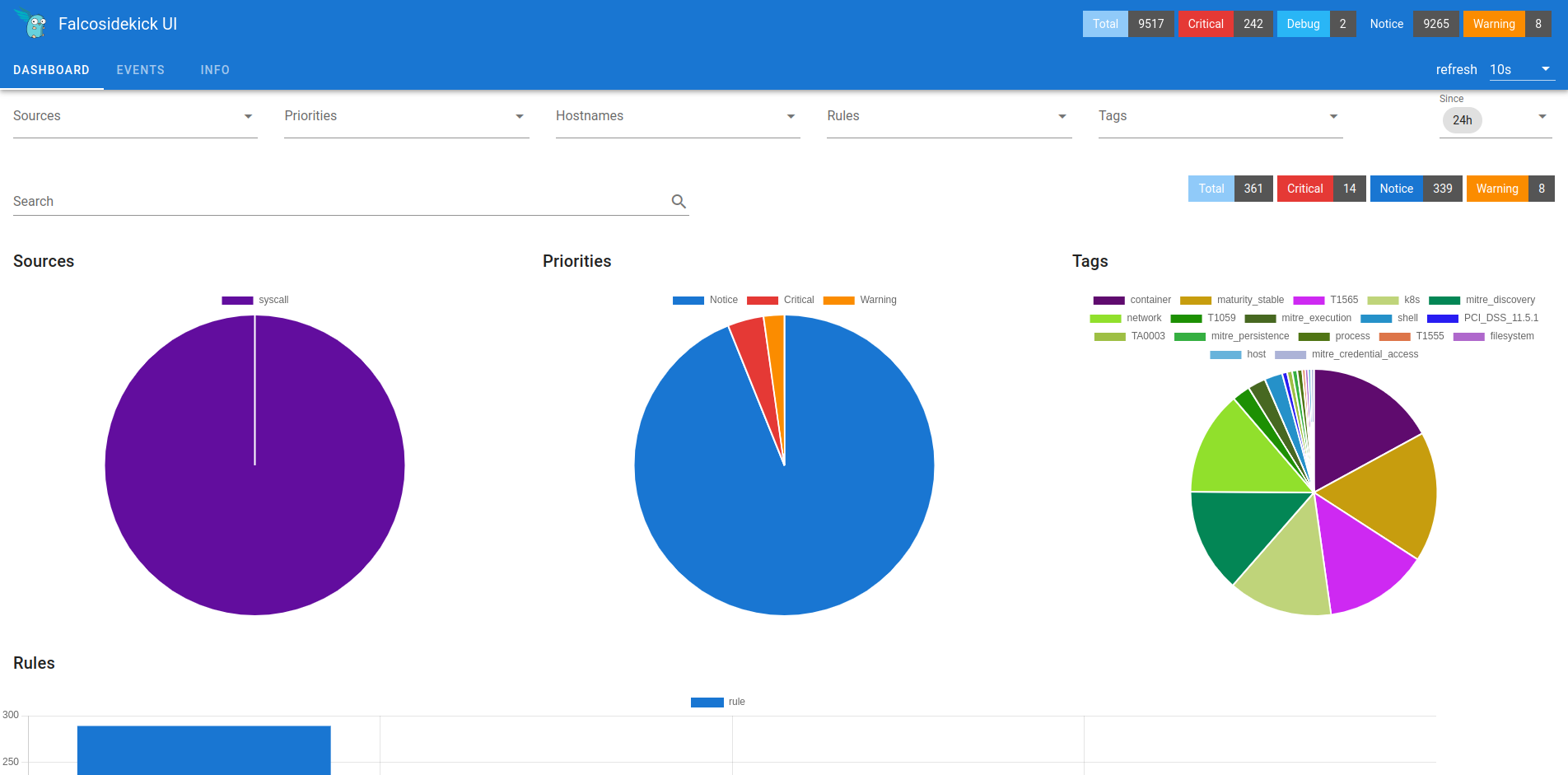
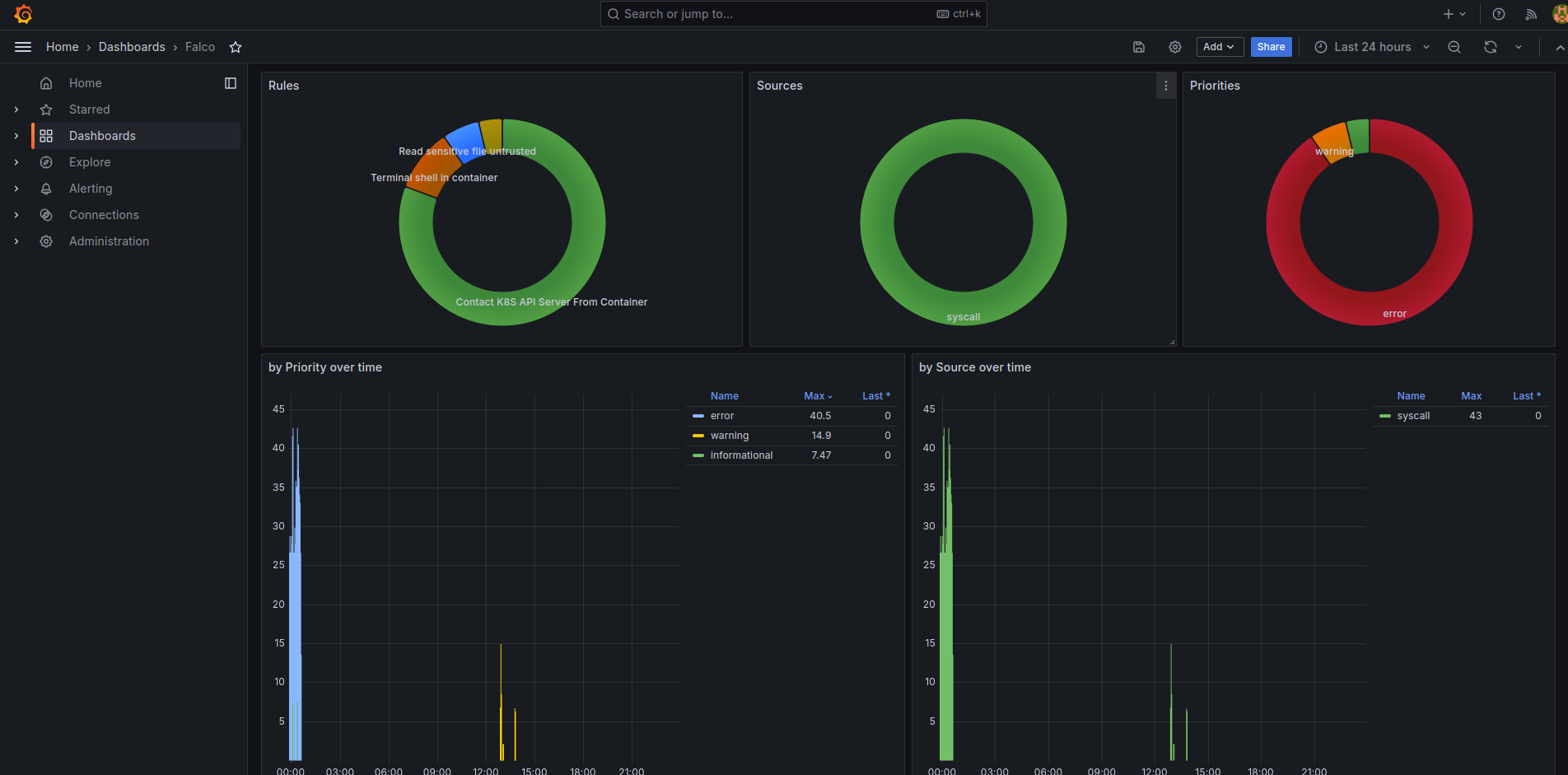
Falco Sidekick is in charge of collecting various metrics from Falco, and presenting them through a WebUI. This is an optional component and can be replaced by a Grafana dashboard as well.
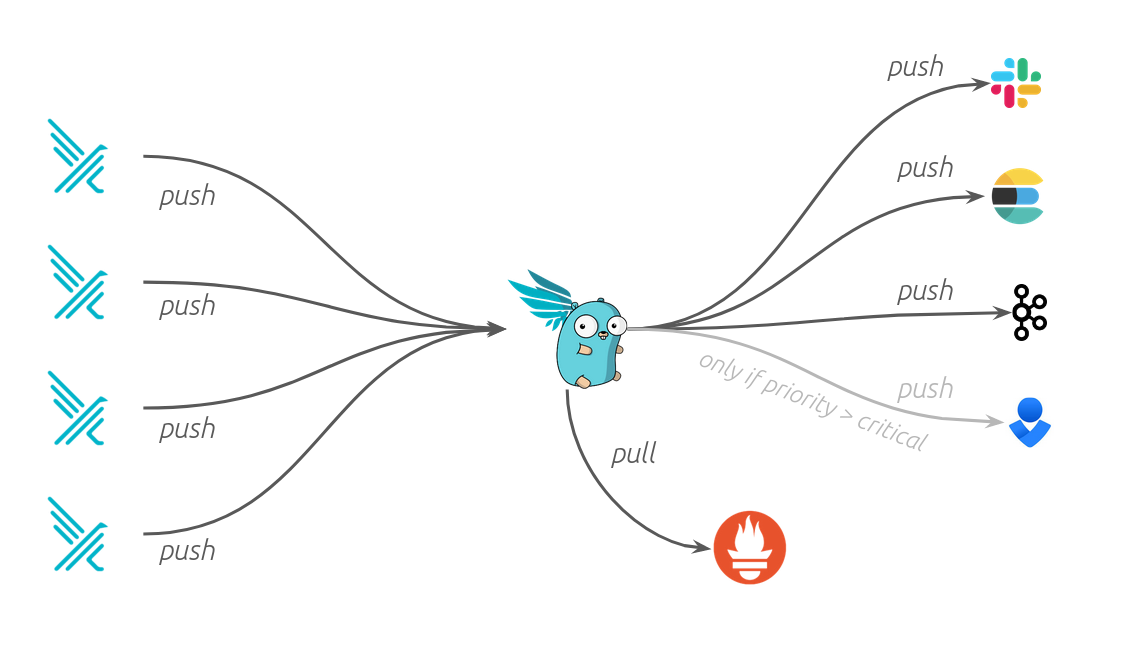
Falco Sidekick is also used to interface with various other components, for example you could send notifications to a security team if a critical event happens in a sandboxed container !
Let's trigger a security event manually to see what happens. To do-so we'll open a shell in the container we created previously and try to open a sensitive file (/etc/shadow).
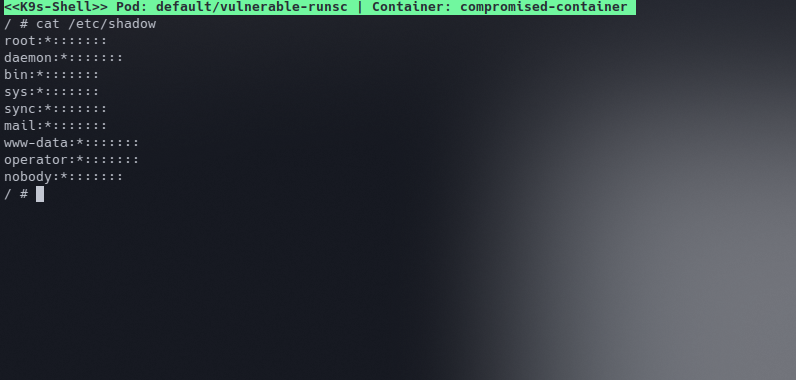
Did Falco catch that ?
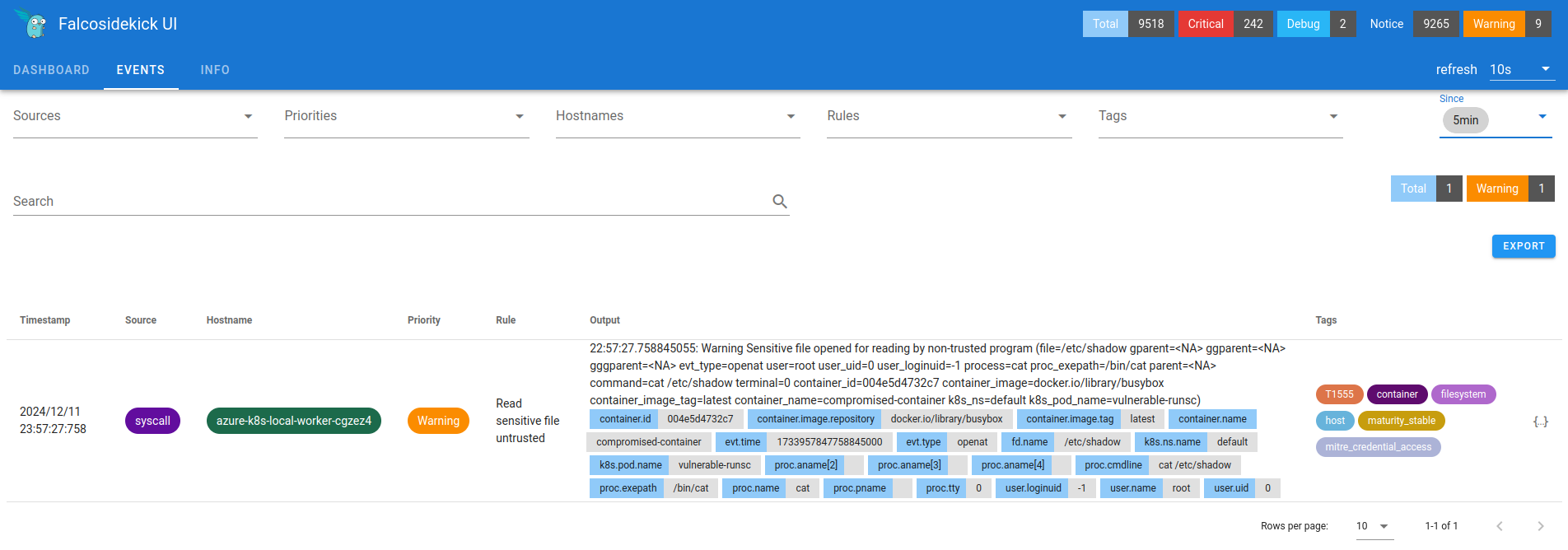
It did ! We're now seen, our massive skill issue caused Falco Sidekick to trigger a PagerDuty alarm, and the security team is already cursing at you for disturbing them during their CS2 game.
Obviously, Falco comes packaged with various rules, but you're free to extend this catalog with your own and assign them different criticality levels. (https://falco.org/docs/rules/basic-elements/).
Rules are based on an event (such as a syscall), and will be evaluated against different conditions, for example the rule...:
- rule: shell_in_container
desc: notice shell activity within a container
condition: >
evt.type = execve and
evt.dir = < and
container.id != host and
(proc.name = bash or
proc.name = ksh)
output: >
shell in a container
(user=%user.name container_id=%container.id container_name=%container.name
shell=%proc.name parent=%proc.pname cmdline=%proc.cmdline)
priority: WARNING... looks for execve syscalls, and check if the process starting is a shell (bash/ksh), which could indicate a container takeover. The evt.dir variable is a bit confusing, it is not a directory, but the direction of the syscall, this is explained in more details in Falco's documentation.
Caveats
Workload support
Even though gVisor benefits from active development, with a good suite of automated tests, there will always be hidden bugs because of the nature of runsc. Writing a user-mode kernel is no mean feat, and ensuring its full-compatibility with a real linux kernel is an even harder task.
As they say quite clearly on their website:
The only real way to know if it will work is to try.
Performance overhead
Obviously, introducing an intermediate layer for sandboxing comes with a slight performance penalty, but still less than traditional virtualization, let's compare different metrics between runc and runsc.
Memory operations per second is almost equal between the two, this is because the only overhead added by runsc is when mapping the memory segment, not during memory access.

Memory usage is slightly increased due to the additional sandboxing components, however this overhead in size does not scale linearly with the sandboxed container memory usage.
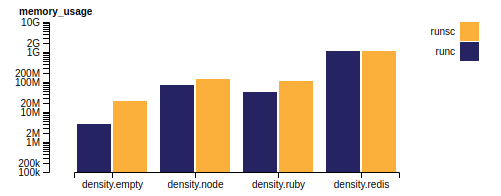
CPU Events per second are equal, as runsc is not re-interpreting anything here.

Systemcall times however... are hum... impacted by runsc, as they are handled by a user-mode kernel and some of them will even require runsc to make another syscall to the host in order to serve the first one. However this depends on the platform, systrap (the default platform since mid-2023), will have a severe syscall overhead; on the other hand runsc on kvm platform has even slower latency than runc, but comes with the downside that it has to be run in a bare-metal environment.
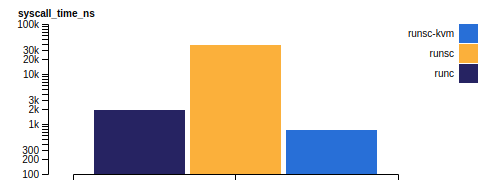
The gVisor team made a complete benchmark that gives really good insights on where runsc performs well, and where it doesn't, so I highly recommend you read it before going down the sandboxing route.
Conclusion
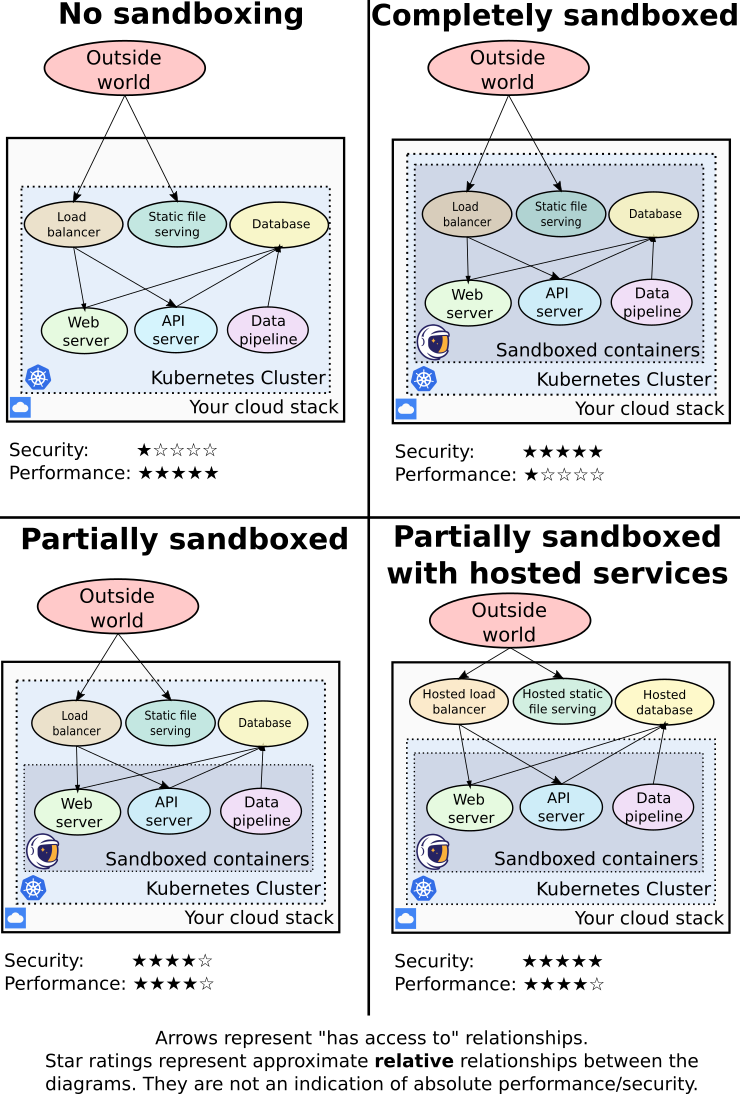
Hopefully you learned some things about container sandboxing and monitoring. Now let's imagine you're ready to deploy gVisor on your Kubernetes cluster, how should you go about it ?
gVisor's team recommendation, is to only sandbox what is truly needed, and to try and isolate risky services on specific nodes; as-well as offloading "core" components such as your ingress controller to cloud services if possible in order to get the best tradeoff between security and performance.
If you notice an error in the post, feel free to hit me up on GitHub 😄